Here is one of the most complicated and debated choice in the open source world. Selecting your relational database system.
I will speak here only of MySQL and PostgreSQL as they are the databases systems.
Raw Data
Let’s start with some raw data comparison before going into details (Let’s put SQL Server too here for comparison):
| Information | MySQL | PostgreSQL | Microsoft SQL Server |
|---|---|---|---|
| Licence | GNU GPL or proprietary | PostgreSQL | Proprietary |
| Year of creation | 1995 | 1996 (based on Ingres, 1982) | 1989 |
| Main contributors | Oracle, Google, Percona, | EnterpriseDB, 2ndQuadrant | Microsoft |
| Projects/Companies using it | Facebook, Github, LinkedIn, Flickr, Wikipedia, Twitter, Digg | Openstreetmap, Disqus, Yahoo, Reddit, Skype, Github | Microsoft, StackOverflow |
| Slogan | The most popular open source database | The world’s most advanced open source database | None ? |
| Last version | 5.7 | 9.6 | 2016 |
Take in considerations that projects and companies using them are not exclusive, for example, LinkedIn also use Apache Cassandra and probably more :)
Clichés and misconceptions

Credits to myfrenchlife.org
Something to know if that both MySQL and PostgreSQL have their clichés, I will try to explain them and tell you if they are true or not.
PostgreSQL
PostgreSQL is slow !
WRONG !
This was true in the early versions of PostgreSQL and even before, but since Postgresql 8.0, there has been a LOT of improvements in term of speed. PostgreSQL has similar performances with MySQL.
PostgreSQL is complicated !
WRONG !
This is maybe one of the things you will see the most in the forums around (Especially from MySQL fanboys), PostgreSQL is not more complicated than MySQL. What will usually scare people is that you will not have all those nonstandard SHOW commands that make your life easier. In PostgreSQL, we prefer to use standard SQL queries on tables, or views, to have the equivalent, or there are some meta commands available in the psql shell, and for many things, PostgreSQL is actually far easier than MySQL for everyday life (excluding specific stuff like advanced replication with failover or PITR), here is a simple example, wanna know the size of a database ?
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
--------------------------+---------+----------+---------+-------+-------------------+---------+------------+--------------------------------------------
django | django | UTF8 | C | C | | 9513 kB | pg_default |
postgres | kedare | UTF8 | C | C | | 7151 kB | pg_default | default administrative connection database
spring | spring | UTF8 | C | C | | 7065 kB | pg_default |
template0 | kedare | UTF8 | C | C | =c/kedare +| 7041 kB | pg_default | unmodifiable empty database
| | | | | kedare=CTc/kedare | | |
template1 | kedare | UTF8 | C | C | =c/kedare +| 7041 kB | pg_default | default template for new databases
| | | | | kedare=CTc/kedare | | |
(7 rows)vs MySQL:
mysql> SELECT table_schema "Data Base Name",
-> sum( data_length + index_length ) / 1024 / 1024 "Data Base Size in MB",
-> sum( data_free )/ 1024 / 1024 "Free Space in MB"
-> FROM information_schema.TABLES
-> GROUP BY table_schema ;
+--------------------+----------------------+------------------+
| Data Base Name | Data Base Size in MB | Free Space in MB |
+--------------------+----------------------+------------------+
| information_schema | 0.15625000 | 80.00000000 |
| mysql | 2.42471313 | 4.00000000 |
| performance_schema | 0.00000000 | 0.00000000 |
| sys | 0.01562500 | 0.00000000 |
+--------------------+----------------------+------------------+
4 rows in set (0.07 sec)This is of course, without installing any tool others than the bundled ones, of course, you can do a similar query with PostgreSQL, actually this is what this meta command does in the background, you can see it on the Postgres process, if for example you have it running in a terminal with the -d3 option (What I do for development) :
SELECT d.datname as "Name",
pg_catalog.pg_get_userbyid(d.datdba) as "Owner",
pg_catalog.pg_encoding_to_char(d.encoding) as "Encoding",
d.datcollate as "Collate",
d.datctype as "Ctype",
pg_catalog.array_to_string(d.datacl, E'\n') AS "Access privileges",
CASE WHEN pg_catalog.has_database_privilege(d.datname, 'CONNECT')
THEN pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname))
ELSE 'No Access'
END as "Size",
t.spcname as "Tablespace",
pg_catalog.shobj_description(d.oid, 'pg_database') as "Description"
FROM pg_catalog.pg_database d
JOIN pg_catalog.pg_tablespace t on d.dattablespace = t.oid
ORDER BY 1;Another example for you, wanna know what is the configuration file used by the server process? PostgreSQL :
postgres=# SHOW config_file;
config_file
--------------------------------------------------------------
/Users/kedare/Documents/Databases/Postgresql/postgresql.conf
(1 row)MySQL, Well… You know what? There is no way to know what is the loaded configuration file on your server instance. Well if you are playful you can restart your process with an attached strace, you may have a list of the default configuration files that will be loaded when your server process when running it with mysqld --verbose --help but nothing about the actually loaded file.
PostgreSQL sucks at scaling out
Kind of
Well… This is I think the worst point about PostgreSQL.
If you want a simple master-slave replication, it can be done in a few minutes (Thanks, pg_basebackup -R). If you want something similar to SQL Server Database Mirroring, meaning a master-slave replication with automatic failover and master election. Well, good luck :)
There are some ways to do this, I had the occasion to have (Well to try to setup this) using Postgresql 9.6, PGPool2 and REPMGR and this has been hell, after many days trying to have it working, I gave up.
There are other solutions that would require more knowledge that I didn’t try like Stolon that makes this kind of stuff more or less automatic but require knowledge of Kubernetes. In my case, the deployment was for production systems and I don’t know a lot about Kubernetes so that was a big no (But Stolon itself looks great).
So for this point, I would say, it really depends on of what you are looking for and of the time you wanna spend setting it up.
MySQL
MySQL is not ACID compliant
WRONG!
This has been true like 15 years ago at the MyISAM era. Today, everyone should use InnoDB or any equivalent storage engine that is completely ACID compliant.
MySQL doesn’t care about your data
WRONG!
MySQL cares about your data as much as you tell him to, you want it to take care of your data? use STRICT mode and InnoDB. Fortunately, if you are using a recent version of MySQL, this should be your default.
MySQL doesn’t have hot backups
WRONG!
Again, this is from the MyISAM era, but you will still see a lot of people that will think that MySQL cannot do hot backup without any locking. OF COURSE IT CAN. Thanks transactions and InnoDB.
Presenting themselves
Let’s check some of the “official” presentations of both of them.
MySQL Community Edition
MySQL is a database management system.
A database is a structured collection of data. It may be anything from a simple shopping list to a picture gallery or the vast amounts of information in a corporate network. To add, access, and process data stored in a computer database, you need a database management system such as MySQL Server. Since computers are very good at handling large amounts of data, database management systems play a central role in computing, as standalone utilities, or as parts of other applications.
Obviously.
MySQL databases are relational.
A relational database stores data in separate tables rather than putting all the data in one big storeroom. The database structures are organized into physical files optimized for speed. The logical model, with objects such as databases, tables, views, rows, and columns, offers a flexible programming environment. You set up rules governing the relationships between different data fields, such as one-to-one, one-to-many, unique, required or optional, and “pointers” between different tables. The database enforces these rules, so that with a well-designed database, your application never sees inconsistent, duplicate, orphan, out-of-date, or missing data.
The SQL part of “MySQL” stands for “Structured Query Language”. SQL is the most common standardized language used to access databases. Depending on your programming environment, you might enter SQL directly (for example, to generate reports), embed SQL statements into code written in another language, or use a language-specific API that hides the SQL syntax.
SQL is defined by the ANSI/ISO SQL Standard. The SQL standard has been evolving since 1986 and several versions exist. In this manual, “SQL-92” refers to the standard released in 1992, “SQL:1999” refers to the standard released in 1999, and “SQL:2003” refers to the current version of the standard. We use the phrase “the SQL standard” to mean the current version of the SQL Standard at any time.
Yes, MySQL does use MySQL but it’s not the most standard SQL you could find (PostgreSQL and MSSQL are both better on this point)
MySQL software is Open Source.
Open Source means that it is possible for anyone to use and modify the software. Anybody can download the MySQL software from the Internet and use it without paying anything. If you wish, you may study the source code and change it to suit your needs. The MySQL software uses the GPL (GNU General Public License), http://www.fsf.org/licenses/, to define what you may and may not do with the software in different situations. If you feel uncomfortable with the GPL or need to embed MySQL code into a commercial application, you can buy a commercially licensed version from us. See the MySQL Licensing Overview for more information (http://www.mysql.com/company/legal/licensing/).
Yes it is open source, but not completely, MySQL both has the community edition, and many other proprietary editions that are closed source and paid, so Oracle being the “owner” of MySQL (Well, of the brand at least), they will have some features not included in the open source edition, for example a thread pool that would increase the performance, or some backup tools (that have open source alternative), or the MySQL Enterprise Firewall that would allow to blacklist/whitelist query patterns.
PostgreSQL
PostgreSQL is a powerful, open source object-relational database system. It has more than 15 years of active development and a proven architecture that has earned it a strong reputation for reliability, data integrity, and correctness. It runs on all major operating systems, including Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64), and Windows. It is fully ACID compliant, has full support for foreign keys, joins, views, triggers, and stored procedures (in multiple languages). It includes most SQL:2008 data types, including INTEGER, NUMERIC, BOOLEAN, CHAR, VARCHAR, DATE, INTERVAL, and TIMESTAMP. It also supports storage of binary large objects, including pictures, sounds, or video. It has native programming interfaces for C/C++, Java, .Net, Perl, Python, Ruby, Tcl, ODBC, among others, and exceptional documentation.
We will talk later about the “object-relational database system” thing.
Technical overview
Let’s talk more technical.
Here are the questions you need to ask you when you have to choose between those database systems.
Do you need complex data types ? (Object database or GIS)
This is one of the big things of PostgreSQL, it’s not just an RDBMS that thinks of tables and simple datatypes, it’s an ORDBMS where you have advanced types, here are some examples:
Network related types
This may be useful to you if you are from the telecom world, PostgreSQL support natively IPv4, IPv6 addresses, subnets, and MAC address, and thanks for the object oriented database, PostgreSQL has built-in operators for those that would allow you for example to do this kind of things:
postgres=# SELECT '2001:4f8:3:ba::32'::inet <<= '2001:4f8:3:ba::/64'::inet;
?column?
----------
t
(1 row)
postgres=# SELECT '192.168.1.42'::inet <<= '192.168.1.0/24'::inet;
?column?
----------
t
(1 row)Let’s explain those queries.
::inet, the :: tells PostgreSQL to do casting from on the value (character varying) to the inet type that represents either an IP or a subnet.
As everything is open in PostgreSQL I can, for example, open PgAdmin and explores the pg_catalog catalog (catalogs are like namespaces, more or less like a database in the database).
When checking the catalog, I can see the type definitions and the operators (As the inet type is an internal one, there is no much to see as it’s basically coded in C in the PostgreSQL core), but here is some example of things you could see.
Let’s say I want to add a < operator for the point data type and the = that will call the internal point_eq(point, point) function.
I would first create the function used by this operator and the operators :
create operator = (leftarg = point, rightarg = point, procedure = point_eq, commutator = =);
create function point_lt(point, point)
returns boolean language sql immutable as $$
select $1[0] < $2[0] or $1[0] = $2[0] and $1[1] < $2[1]
$$;
create operator < (leftarg = point, rightarg = point, procedure = point_lt, commutator = >);Then now, I want to make those operators useable with the indexes, I have to create an operator class, but before, the operator class needs a function that would allow the database engine to compare 2 data and sort them:
create function btpointcmp(point, point)
returns integer language sql immutable as $$
select case
when $1 = $2 then 0
when $1 < $2 then -1
else 1
end
$$;Then the operator class :
create operator class point_ops
default for type point using btree as
operator 1 <,
operator 2 <=,
operator 3 =,
operator 4 >=,
operator 5 >,
function 1 btpointcmp(point, point);Examples from this StackOverflow post
Of course, you can have far more complex operators as you can define more or less any operators, and also have support for negation, etc.
Something to know about this, is that for any table you create, PostgreSQL create an equivalent type, here is a small demo :
test=# create table inet_allocation(id serial, network inet unique, description character varying);
CREATE TABLE
test=# select ((0, '192.168.0.0/24'::inet, 'Main office network')::inet_allocation).description;
description
---------------------
Main office network
(1 row)Then you can start using this type anywhere in your database (So basically you have objects with operators and attributes, also useable in your stored procedures).
Unfortunately, MySQL doesn’t offer anything for custom data types, operators overloading or object orientation. So if you plan to use those features (You will probably not if you are using an ORM), PostgreSQL is a good candidate.
About GIS, PostgreSQL is probably the most advanced database (of all), I’m not an expert in GIS, but I found many articles saying so. Also, OpenStreetMap us using it (was using MySQL before).
MySQL has a limited GIS support (Geometrical only, no geography, limited to SRID 0 “Infinite flat Cartesian plane with no units assigned to its axes.” )
Do you need advanced JSON features ?
Here is another domain where PostgreSQL shines, sometimes called “Better MongoDB than MongoDB”. PostgreSQL has an excellent JSON support.
You can store JSON-like on most of the databases, but you can also put index and constraints on your JSON fields, and thanks again to the object system, there are operators to do most of what you need.
For this part, I will redirect you to this article that has all the example I would like to show you: https://www.compose.com/articles/is-postgresql-your-next-json-database/
MySQL has a quite limited feature set on JSON, yes it has JSON support but it’s FAR from being sexy like on PostgreSQL.
You can forget indexes or constraints like on PostgreSQL, you will have to rely on generated columns, that is far less… interesting. And you need a very recent version of MySQL, at least 5.7.6, here is what is looks like:
mysql> CREATE TABLE jemp (
-> c JSON,
-> g INT GENERATED ALWAYS AS (c->"$.id"),
-> INDEX i (g)
-> );
Query OK, 0 rows affected (0.28 sec)
mysql> INSERT INTO jemp (c) VALUES
> ('{"id": "1", "name": "Fred"}'), ('{"id": "2", "name": "Wilma"}'),
> ('{"id": "3", "name": "Barney"}'), ('{"id": "4", "name": "Betty"}');
Query OK, 4 rows affected (0.04 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> SELECT c->>"$.name" AS name
> FROM jemp WHERE g > 2;
+--------+
| name |
+--------+
| Barney |
| Betty |
+--------+
2 rows in set (0.00 sec)
mysql> EXPLAIN SELECT c->>"$.name" AS name
> FROM jemp WHERE g > 2\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: jemp
partitions: NULL
type: range
possible_keys: i
key: i
key_len: 5
ref: NULL
rows: 2
filtered: 100.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
mysql> SHOW WARNINGS\G
*************************** 1. row ***************************
Level: Note
Code: 1003
Message: /* select#1 */ select json_unquote(json_extract(`test`.`jemp`.`c`,'$.name'))
AS `name` from `test`.`jemp` where (`test`.`jemp`.`g` > 2)
1 row in set (0.00 sec)Let’s hope that MySQL will get something better in the future. (Most of the limitations are related to the leak of having an extensible typing system like PostgreSQL).
Do you need CTE ?
I’ll be short here, MySQL doesn’t have CTE support (yet).
This is a planned feature for MySQL 8.0.
Do you need advanced indexes ?
Here are some kind of indexes supported by PostgreSQL and not MySQL (yet?)
- Functionnal indexes
- Partial indexes
- Unaccented indexes (Functional indexes + unaccent)
- Trigram indexes
Do you plan to scale out easily ?
Here is where MySQL shines, especially in the last versions, you have 2 official solutions to reach a real H.A, both are really easy to setup.
MySQL Group Replication
Ever hear of MongoDB replication set? Here you will have something similar, a master-slave replication system, managed automatically, new members can join without any action, and failover is managed automatically using quorum.
https://dev.mysql.com/doc/refman/5.7/en/group-replication.html
Here is a typical architecture with MySQL Group Replication :
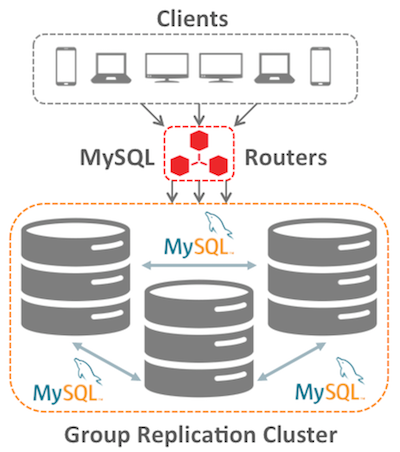
MySQL Cluster
Here is another H.A system for MySQL, this one is master-master
It doesn’t work like a standard MySQL, and it required more nodes than the group replication, basically you will have NDB nodes that will host the data itself (and it needs to fit in memory), the SQL nodes that will basically be MySQL instances querying your NDB tables from the NDB hosts and then you have others nodes used for management.
This mode has limitations and will probably required some changes from a standard MySQL application, so before starting deploying it, READ the documentation :
https://dev.mysql.com/doc/refman/5.7/en/mysql-cluster.html
Here is the typical architecture with MySQL Cluster
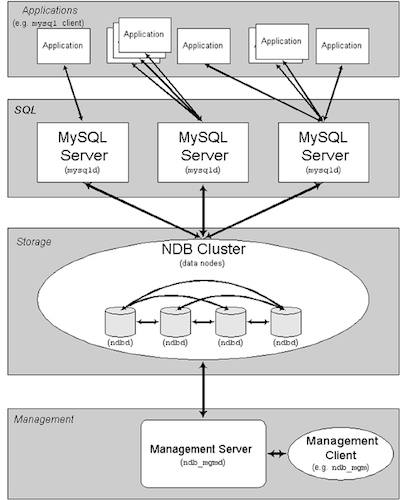
If you want to play with MySQL cluster, I invite you to read this article so you can get your cluster ready in a few minutes : http://mikaelronstrom.blogspot.com.es/2017/01/mysql-cluster-up-and-running-in-less.html
PostgreSQL
PostgreSQL doesn’t have any official solution for this kind of high availability, the PostgreSQL core offers replication, but nothing that would allow automatic failover.
There are some projects trying to achieve high availability, I can’t talk much about them as I either just read about them (Postgres-XL) or played a very little bit (Stolon over Kubernetes).
PostgreSQL Stolon
https://github.com/sorintlab/stolon
stolon is a cloud native PostgreSQL manager for PostgreSQL high availability. It’s cloud native because it’ll let you keep an high available PostgreSQL inside your containers (kubernetes integration) but also on every other kind of infrastructure (cloud IaaS, old style infrastructures etc…)
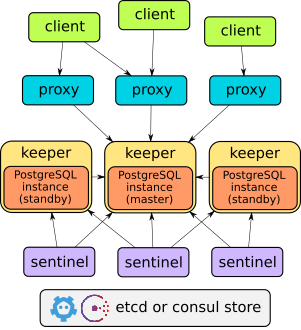
It can be deployed in a few minutes in a Kubernetes cluster, from my test it was working quite fine, but I didn’t have the required knowledge to put a Kubernetes cluster in production, so I didn’t explore more yet this solution as I preferred to learn Kubernetes first (Not just for this but in general).
Postgres-XL
Postgres-XL is a horizontally scalable open source SQL database cluster, flexible enough to handle varying database workloads:
- OLTP write-intensive workloads
- Business Intelligence requiring MPP parallelism
- Operational data store
- Key-value store
- GIS Geospatial
- Mixed-workload environments
- Multi-tenant provider hosted environments
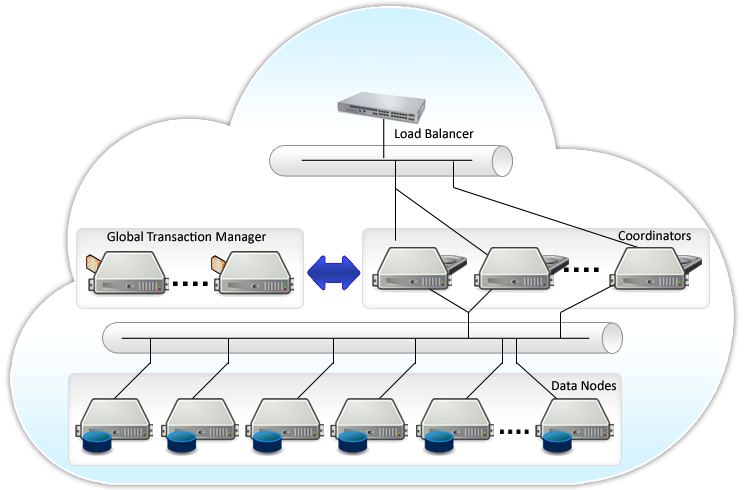
This is a fork of PostgreSQL made for scaling-out. I didn’t have the occasion to experiment with it, as I think, from what I’ve read that it is probably overkill for most of the deployments.
Also, check the What’s Coming section as some features will be merged to PostgreSQL.
Differences in the permission system between MySQL and PostgreSQL
Something interesting to know is the difference on the permission management and ownership system of MySQL and PostgreSQL.
In PostgreSQL, everything has an owner, even a database. When you create the database, you have to specify an owner that will have full right on it (the connected user by default).
In MySQL, there is no concept of owner. You just have to specify the path to the database or tables when you GRANT a permission.
For me, the PostgreSQL way is better. As this allow simple scenarios like allow a user to create databases and gives it full right on them, to do the equivalent in MySQL you have to basically give the grant to the user to databases starting with a common prefix, like this:
GRANT ALL PRIVILEGES ON 'testuser\_%'.* TO 'testuser'@'%';In PostgreSQL, just do :
ALTER USER testuser WITH CREATEDBWhat’s coming ?
PostgreSQL 10
Here is a summary of the information I found on the coming features and improvements on PostgreSQL 10:
- Logical Replication (Selective replication, seamless upgrades)
- Parallelism
- Optimizer & Statistics (Better query planning)
- Transactions & Programmability (Autonomous transactions)
- Management features for Replication & Backup (Parallel backups, Snapshots on standby)
- Locking & Data Availability (Lock free DDL, WAIT PATIENTLY)
- Distributed Systems (Node Registry, Feeding back from Postgres-XL into Core Postgres)
- Real Partitioning
- Asynchronous Foreign Data Wrapper
- Multimaster cluster with sharding
- JIT-compilation of queries
- Pluggable storages
- Block-level incremental backup
- Backup validation
MySQL 8
- InnoDB System Catalog: No more MyISAM based MySQL.* schema. NO MORE .FRM
- Roles: You can now define roles for the user’s accounts and inherit permissions or parameters.
- InnoDB temporary tables are now on a separated tablespace
- InnoDB tablespace encryption
- Invisible index: Allows to make indexes invisible, so you can disable and enable them without having to overhead of the index deletion and creation
Summary
Here is a little summary of the go and no-go for MySQL and PostgreSQL :
| Subject | MySQL | PostgreSQL |
|---|---|---|
| I want easy H.A. | YES | NO |
| I want easy PITR | YES | NO |
| I want good management GUI’s | YES | NO |
| I want GIS. | NO | YES |
| I want commercial support | YES | YES |
| I’m an open source extremist | NO | YES |
| I want transactional DDL. | NO | YES |
| I want integration with LDAP. | NO | YES |
| I want to write advanced procedures. | NO | YES |
| I want functional indexes. | NO | YES |
| I want partitioning. | YES | NO |
Bonus
Cool Projects
PostgreSQL
- GPU Accelerated queries: https://wiki.postgresql.org/wiki/PGStrom
- Postgresql + Kubernetes H.A: https://github.com/sorintlab/stolon
MySQL
- MySQL H.A orchestration tool: https://github.com/outbrain/orchestrator
- DBA Framework for MySQL: https://github.com/shlomi-noach/common_schema
- DBA Toolkit for MySQL: https://github.com/mysql/mysql-sys
- InnoDB Recovery Tool: https://bitbucket.org/Marc-T/undrop-for-innodb
Last words
I hope this article helped you in your decision or with your curiosity.
Feel free to leave comments on this article or in Twitter.